




Are you curious about how to start your journey as a data scientist? Data science is a fascinating field with boundless opportunities, but it can feel overwhelming without a clear plan.
This guide provides an in-depth roadmap to help you navigate the world of data science, covering everything from foundational skills to advanced concepts. Whether you're a beginner or looking to switch careers, this comprehensive guide offers actionable advice and insights to get started.
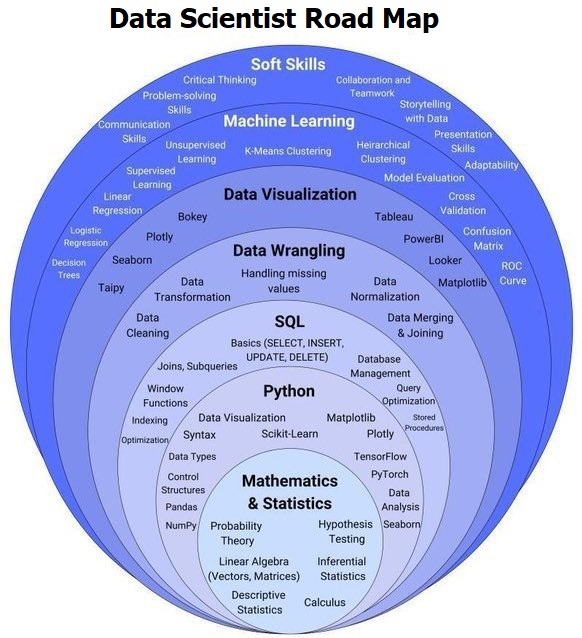
Table of Contents
- Mathematics and Statistics
- Programming with Python
- SQL and Database Management
- Data Wrangling
- Data Visualization Tools
- Machine Learning
- Soft Skills
- Additional Concepts
- Conclusion
Mathematics and Statistics
Mathematics and statistics are the fundamental pillars of data science, providing the theoretical and practical tools necessary to analyze, interpret, and model data. A firm grasp of these disciplines is advantageous—it is essential for understanding the algorithms and techniques that drive the field. Without these fundamentals, data science methods, including machine learning, data visualization, and predictive analytics, cannot be effectively applied.
Mathematics and statistics are indispensable for any data scientist. These disciplines equip professionals with the tools to analyze data, develop predictive models, and derive actionable insights, making them the proper building blocks of this dynamic field.
Probability Theory
Probability is a key aspect of data science, enabling predictions about future events and assessments of uncertainty. Conditional probability, Bayes' theorem, and probability distributions are core concepts used to model and infer relationships within data. These principles underpin many machine learning algorithms and statistical models.
In fraud detection systems, probability is used to identify abnormal transactions by comparing them to historical patterns. This reduces risks and improves accuracy in real-time decision-making.
Linear Algebra
Linear algebra is critical in machine learning, where operations on vectors and matrices are frequent. Concepts like matrix multiplication and eigenvalues are integral to algorithms like Principal Component Analysis (PCA) and Singular Value Decomposition (SVD). These tools help reduce the dimensionality of large datasets, making analysis computationally feasible.
Netflix applies linear algebra through matrix factorization to provide personalized content recommendations. The platform predicts what users will likely watch next by analyzing user interactions and preferences.
Descriptive Statistics
Descriptive statistics help summarize and organize data to provide a clear overview of its structure and characteristics. By calculating statistical measures like mean, median, mode, and standard deviation, data scientists can uncover patterns and assess variability within datasets. These statistics are the first step in any exploratory data analysis (EDA) process, laying the groundwork for deeper insights.
Calculus
Calculus is fundamental in machine learning, particularly in optimization tasks. For instance, gradient descent, a widely used algorithm in training neural networks, relies on derivatives to find the optimal weights that minimize error. Calculus also aids in understanding changes in data relationships, which is critical for creating robust models.
Hypothesis Testing
Hypothesis testing determines whether a result is statistically significant, ensuring that findings are not due to random chance. This method is central to experimental design and A/B testing, where two versions of a product or strategy are compared to measure their effectiveness.
Inferential Statistics
Inferential statistics extend insights from a sample to a broader population, enabling predictions and generalizations. Confidence intervals and hypothesis tests are essential for drawing meaningful conclusions.
Inferential statistics are often employed in survey analysis to predict population trends based on responses from a small sample group. This provides actionable insights into business and policymaking.
Programming with Python
Python has become the cornerstone programming language in data science due to its user-friendly syntax and extensive ecosystem of libraries tailored for data manipulation, analysis, and machine learning. Whether you're a beginner or an experienced professional, Python offers tools and functionality to tackle virtually any data science problem.
Syntax and Data Types
Mastering Python's syntax is the first step toward becoming proficient. Its simplicity allows beginners to focus on problem-solving rather than struggling with complex syntax. Understanding data types such as lists, tuples, dictionaries, and sets is equally essential, as these structures allow for efficient data storage and manipulation.
Lists are often used to store datasets, while dictionaries are ideal for key-value pair data, such as mapping customer IDs to purchase histories.
Control Structures
Control structures like loops (for, while) and conditionals (if-else) are critical for automating repetitive tasks and making dynamic decisions in your programs.
In a real-life data analysis application, loops can iterate over rows in a dataset to calculate specific metrics, such as the average sales per product category.
Libraries: Pandas and NumPy
Python's libraries significantly enhance its capabilities for data manipulation and computation.
Pandas:
It is known as the go-to library for data manipulation. It provides DataFrames, two-dimensional, tabular data structures that simplify cleaning and analyzing structured datasets.
A retail business can use Pandas to clean messy sales data by removing duplicates and filling in missing values.
NumPy:
This library is essential for numerical computing. Its array objects allow high-performance operations on large datasets, including matrix multiplication and mathematical transformations.
In image processing, NumPy arrays represent pixel data for efficient computations.
Data Visualization: Matplotlib and Seaborn
Visualization is a key part of data science, and Python offers powerful libraries for creating compelling visual representations of data.
Matplotlib:
This tool enables the creation of static, animated, and interactive plots. It provides low-level control, making it highly customizable.
Seaborn:
Built on Matplotlib, Seaborn simplifies creating aesthetically pleasing statistical plots.
Using Seaborn, a data scientist can visualize customer churn trends through heatmaps or box plots, making it easier to identify patterns.
Machine Learning: Scikit-Learn and TensorFlow
Thanks to its advanced libraries, machine learning is one of Python's strongest domains.
Scikit-Learn:
This library is well-suited for applying traditional machine learning methods, including regression, classification, and clustering. Its built-in tools for model evaluation and feature selection make it indispensable.
A data scientist can use Scikit-Learn to build a predictive model that estimates house prices based on features like size and location.
TensorFlow:
TensorFlow is a well-known library for deep learning. It enables the design, training, and deployment of neural networks.
TensorFlow powers applications like image recognition in self-driving cars or sentiment analysis in social media platforms.
Data Analysis Techniques
Python's libraries collectively support robust exploratory data analysis (EDA), a process where data is summarized and visualized to uncover patterns, trends, and anomalies. EDA is often the first step in any data science project.
In financial data analysis, Pandas and Matplotlib can be used together to visualize stock price trends and detect outliers.
Python's versatility, combined with its vast array of libraries, makes it an indispensable tool in every data scientist's toolkit. You can unlock insights and build impactful data-driven solutions by mastering its syntax, leveraging its libraries, and applying its tools effectively.
SQL and Database Management
Data is the lifeblood of data science, and databases serve as its repositories. Structured Query Language (SQL) is a necessary skill for data scientists, allowing them to interact with relational databases efficiently. Whether retrieving data for analysis or optimizing database performance, SQL is a foundational tool in the data science arsenal.
Basic Operations
At its core, SQL provides commands to retrieve and manipulate data.
-
SELECT: Used to fetch specific data from a database.
-
INSERT: Allows new data to be added to a table.
-
UPDATE: Modifies existing records in a database.
-
DELETE: Removes data from a table.
-
Example: A data scientist working with a customer database may use SELECT to pull customer names and purchase histories or UPDATE to correct errors in contact information.
Joins and Subqueries
SQL joins are indispensable when working with multiple tables. They allow data scientists to combine datasets based on shared keys.
-
Inner Join: Retrieves rows that have matching values in both tables.
-
Left Join: Includes all rows from the left table and matching rows from the right table.
-
Right Join: Includes all rows from the right table and matching rows from the left table.
Subqueries are nested queries that provide intermediate results to a main query, enabling complex operations.
An e-commerce company might use a join to combine sales data with customer demographics, creating insights into purchasing behavior.
Window Functions
Window functions calculate values across a specific range of rows in a dataset. They can also table rows related to the current row without collapsing the data into a single result. They are beneficial for ranking, calculating cumulative sums, and creating moving averages.
A sales database might use a window function to rank products based on total revenue or calculate a cumulative sales total for the year.
Indexing and Optimization
Indexing is critical for improving query performance, especially with large datasets. An index allows the database to locate and retrieve rows faster than table scanning.
In a database with millions of customer records, indexing the customer_id column significantly reduces the time required to retrieve data for a specific customer.
Query optimization involves minimizing redundant queries, avoiding unnecessary joins, and effectively using indexed columns to speed up database operations.
Stored Procedures
Stored procedures are precompiled sets of SQL queries that can be executed as a single program. They enhance efficiency by reducing redundancy and ensuring consistent query execution.
A data scientist might create a stored procedure to automate the monthly extraction of sales data, eliminating the need to rewrite queries each time.
SQL is more than just a language; it bridges raw data and actionable insights. By mastering SQL's foundational commands, understanding its advanced features like joins and window functions, and optimizing database performance through indexing and stored procedures, data scientists can open the full potential of their datasets. Whether analyzing sales trends, customer behavior, or operational metrics, SQL remains an indispensable skill in every data scientist's toolkit.
Data Wrangling
Data wrangling is a crucial step in the data science process. It involves transforming raw, messy data into a structured and usable format. This stage is often the most time-consuming, as datasets are rarely ready for analysis right out of the box. Effective data wrangling ensures that data is clean, consistent, and ready to yield meaningful insights.
Data Cleaning
Data cleaning is the foundation of data wrangling. It focuses on identifying and correcting errors, inconsistencies, and inaccuracies in the dataset. Common tasks include:
-
Removing Duplicates: Ensuring that the dataset doesn't contain repeated rows, which can skew analysis.
-
Standardizing Formats: Converting inconsistent formats, such as dates written differently (e.g., MM/DD/YYYY vs. DD-MM-YYYY), into a unified structure.
-
Correcting Errors: Fixing typos, out-of-range values, or invalid entries.
In healthcare analytics, patient records may contain duplicate entries or inconsistent diagnosis coding. Cleaning this data ensures reliable insights into patient outcomes and trends.
Transformation Techniques
Data transformation prepares the dataset for analysis by adjusting its structure and content. Key techniques include:
-
Normalizing Data: Rescaling values to fit within a specific range (e.g., 0 to 1). This is especially useful for algorithms sensitive to feature magnitude, such as gradient descent.
-
Scaling Data involves adjusting data values to ensure comparability, such as converting currencies or units of measurement to a common standard.
-
Encoding Categorical Variables involves converting non-numeric data, such as "Male/Female" or "Yes/No," into numeric formats that algorithms can process.
When analyzing customer demographics, categorical data like "city" or "gender" might be encoded numerically to allow machine learning models to be trained.
Handling Missing Values
Missing data is a common issue in practical world datasets and must be handled thoughtfully to avoid biased results. Strategies include:
-
Removing Rows or Columns: Eliminating rows or columns with a high percentage of missing values, especially when the missing data is not critical.
-
Imputation: Estimating missing values using statistical techniques, such as mean, median, or predictive models.
In a retail dataset, missing customer age values could be filled using the median age of the customer base to retain the dataset's completeness.
Data Normalization
Normalization standardizes the scale of features within a dataset, ensuring that no single feature dominates due to its magnitude. This is particularly important for distance-based algorithms like k-means clustering or support vector machines.
By bringing all features to a similar scale, normalization enhances the performance and stability of machine learning models.
Normalizing variables such as house size and price in predicting housing prices ensures that both features are equally weighted during analysis.
Merging and Joining Data
Combining multiple datasets into a comprehensive dataset is often necessary for enriched analysis. This can be achieved using:
-
Merging: Combining datasets with overlapping columns but different rows.
-
Joining: Integrating datasets based on a common key, such as customer IDs or product codes.
Merging sales data with customer demographic data allows analysts to assess purchase behavior by customer segment in an e-commerce dataset.
Why Data Wrangling Essential
Effective data wrangling ensures the quality and reliability of the dataset, directly impacting the accuracy of downstream analysis and machine learning models. Data scientists can build robust pipelines that consistently produce actionable insights by dedicating time to data cleaning, transformation, and integration.
Well-wrangled data is the cornerstone of successful data science projects, whether detecting fraud, predicting customer churn, or analyzing marketing campaigns.
Data Visualization Tools
Data visualization is a critical skill in data science. It enables the transformation of complex data into clear and compelling insights. Effective visualizations help communicate findings to technical and non-technical audiences, facilitating data-driven decision-making.
Matplotlib, Seaborn, and Plotly
Python offers robust libraries for visualizations, from simple plots to interactive dashboards.
Matplotlib:
-
Features: A versatile library for creating static, animated, and interactive visualizations. It provides granular control over plot elements like axes, colors, and annotations.
-
Use Case: Ideal for line charts, bar, and scatter plots.
A data scientist might use Matplotlib to create a time series graph showing monthly sales trends over a year.
Seaborn:
-
Features: Built on Matplotlib, Seaborn simplifies the creation of visually appealing statistical plots such as box plots, heatmaps, and violin plots.
-
Use Case: Frequently used for exploratory data analysis to understand variable relationships.
A heatmap created with Seaborn could highlight correlations between variables in a dataset, such as age and purchasing behavior.
Plotly:
-
Features: A library for interactive visualizations, including 3D plots and geographic maps. Users can zoom, pan, and interact with plots, making them ideal for presentations.
-
Use Case: Suitable for dashboards and real-time data monitoring.
A Plotly chart could display live tracking of stock prices with interactivity for exploring specific time frames.
Tableau, Power BI, and Looker
These tools are designed for business intelligence, offering advanced capabilities for building dynamic dashboards and reports.
Tableau:
-
Features: It allows a drag-and-drop interface for creating dashboards and visualizations without requiring coding skills. It supports integration with various data sources.
-
Use Case: Popular for creating dashboards to track KPIs across multiple departments.
Tableau can display a sales dashboard that updates automatically to show real-time revenue broken down by region and product.
Power BI:
-
Features: A Microsoft product known for its seamless integration with Excel and other Office tools. It excels at creating interactive reports.
-
Use Case: Frequently used in corporate environments to monitor business operations.
Power BI might be used to build a report tracking employee productivity metrics across multiple teams.
Looker:
-
Features: A cloud-based platform that integrates with databases and uses LookML, its proprietary modeling language.
-
Use Case: Ideal for sharing web-based reports and dashboards with stakeholders.
A marketing team might use Looker to analyze campaign performance by combining data from multiple platforms, such as Google Analytics and social media.
Importance of Data Visualization
Data visualization tools bridge the gap between raw data and actionable insights. These tools visually convey information, enabling stakeholders to quickly grasp trends, relationships, and outliers. Whether through static visualizations in Python or dynamic dashboards in Tableau, effective visualizations ensure that the story behind the data is clear and impactful.
In the hands of a skilled data scientist, these tools enhance understanding and drive meaningful discussions and informed decision-making across industries.
Machine Learning
Machine learning is a fundamental element of data science that enables systems to recognize patterns in data and make predictions or decisions without requiring specific programming for each task. It allows applications to like recommendation engines, fraud detection systems, and predictive analytics, offering unparalleled opportunities to uncover insights from large datasets.
Supervised Learning
Supervised learning trains a model using labeled data, where the connections between inputs and outputs are clearly defined. It is one of the most widely used methods in machine learning.
Linear Regression:
-
Purpose: Predict continuous outcomes based on input features.
-
Use Case: This method is commonly used to predict house prices based on features such as size, location, and amenities.
A real estate agency may use linear regression to forecast property values based on historical sales data.
Logistic Regression:
-
Purpose: Suitable for binary classification problems, the goal is to predict one of two possible outcomes (e.g., yes/no, pass/fail).
-
Use Case: Logistic regression is widely used in fraud detection to predict whether a transaction is legitimate or fraudulent.
A bank could use logistic regression to assess loan approval based on customer profiles.
Decision Trees:
-
Purpose: These models split data into branches to decide on specific conditions. They are intuitive and effective for both classification and regression tasks.
-
Use Case: Used in customer segmentation to classify customers based on purchasing behavior.
An e-commerce platform might use decision trees to identify high-value customers based on purchase frequency and transaction amount.
Unsupervised Learning
Unsupervised learning is applied to datasets without labeled outcomes, identifying hidden patterns or structures within the data.
K-Means Clustering:
-
Purpose: Group data points into clusters based on their similarity.
-
Use Case: Ideal for market segmentation, where customers with similar purchasing habits are grouped.
A retailer might use k-means clustering to divide its customer base into distinct groups for targeted marketing campaigns.
Hierarchical Clustering:
-
Purpose: Creates a hierarchy of clusters, often visualized using a dendrogram, to explore relationships within the data.
-
Use Case: Useful in genetics to group species based on similarities in their DNA sequences.
A healthcare organization could use hierarchical clustering to identify patient subgroups with similar symptoms for personalized treatment plans.
Model Evaluation and Cross-Validation
Model evaluation verifies that a machine learning model maintains its performance on unseen data beyond the data it was trained on. Techniques like cross-validation help assess models' reliability and generalizability.
K-Fold Cross-Validation:
-
Purpose: Split the dataset into k subsets, train the model on k-1 subsets, and validate it on the remaining subset. This process is repeated k times to ensure robust evaluation.
-
Use Case: Commonly used to compare the performance of multiple machine learning algorithms.
A data scientist might use k-fold cross-validation to select the best-performing algorithm for predicting customer churn.
Why Machine Learning Essential
Machine learning has transformed industries by automating complex decision-making processes. Its applications are virtually limitless, from diagnosing diseases to personalizing user experiences. By mastering supervised and unsupervised learning techniques and model evaluation methods like cross-validation, data scientists can create accurate and adaptable models for real-world scenarios.
Whether you're building a predictive model for business or clustering data for exploratory analysis, machine learning enable the tools to turn data into actionable insights.
Soft Skills
Soft skills are sometimes underestimated in data science but are as critical as technical expertise. While coding, analytics, and machine learning power the technical side, soft skills enable data scientists to collaborate effectively, communicate insights, and adapt to evolving challenges. Mastering these skills ensures the delivery of data-driven results and their successful implementation within a team or organization.
Critical Thinking and Problem-Solving
Data scientists must be able to think critically and solve problems creatively. Critical thinking involves identifying the right questions, breaking down complex issues into manageable parts, and designing practical solutions.
A data scientist tasked with reducing customer churn must analyze various data sources to identify patterns, determine root causes, and propose actionable solutions. This might involve testing hypotheses, analyzing customer behaviors, and recommending tailored retention strategies.
Critical thinking helps prioritize tasks and ensure data-driven decisions align with business objectives.
Collaboration and Teamwork
Data scientists rarely work alone. Their roles often involve collaborating with cross-functional teams, including engineers, marketers, and product managers. Strong interpersonal skills are essential for navigating diverse perspectives and building consensus.
In a project to optimize product recommendations, a data scientist might collaborate with engineers to implement algorithms and marketers to align recommendations with campaign goals.
Effective teamwork ensures smoother workflows and fosters innovation through diverse input.
Storytelling with Data
Storytelling with data bridges the gap between complex analytics and actionable insights. It involves crafting a narrative around findings, making them relatable and compelling to non-technical stakeholders.
Instead of merely presenting churn metrics, a data scientist might tell a story about how changes in customer behavior reflect evolving preferences, supplemented with visualizations to highlight key trends.
A compelling narrative ensures decision-makers understand, value, and act upon insights.
Presentation and Communication Skills
Clear and concise communication is critical for translating technical findings into insights that stakeholders can easily comprehend. Whether presenting in a boardroom or discussing with peers, effective communication builds trust and facilitates action.
During a quarterly business review, a data scientist may present findings on sales trends using simplified language and impactful visuals, enabling executives to make strategic decisions.
Good communication ensures insights are preserved in translation, enhancing their practical impact.
Adaptability
The field of data science is evolving rapidly, with new tools, technologies, and methodologies constantly emerging. Adaptability means staying curious, embracing continuous learning, and applying fresh knowledge to solve problems.
To meet project requirements, a data scientist might need to quickly adapt to a new data visualization tool or machine learning library.
Adaptability ensures data scientists remain relevant and effective in a rapidly changing field.
Why Soft Skills Are Essential
While technical expertise lays the groundwork for a successful career in data science, soft skills elevate the impact of a data scientist's work. These skills enable seamless collaboration, effective communication, and innovative problem-solving, ensuring that technical outputs translate into actionable results. Data scientists can bridge the gap between raw data and meaningful impact by developing critical thinking, teamwork, storytelling, communication, and adaptability.
Soft skills aren't just complementary—they're indispensable for navigating the complexities of modern data science.
Additional Concepts
In addition to foundational skills and tools, certain advanced evaluation techniques are critical for assessing the performance of machine learning models. The confusion matrix and Receiver Operating Characteristic (ROC) curve are essential concepts in evaluating model performance. These tools provide a deeper understanding of how well a model is performing and where improvements can be made.
Confusion Matrix
A confusion matrix is a structured table that evaluates and summarizes a classification model's performance. It compares the model's predicted and actual outcomes, offering a detailed breakdown of correct and incorrect predictions.
A confusion matrix consists of four key metrics:
-
True Positives (TP): The model correctly predicted positive outcomes.
-
True Negatives (TN): The model correctly predicted negative outcomes.
-
False Positives (FP): The model incorrectly predicted positive outcomes.
-
False Negatives (FN): The model incorrectly predicted negative outcomes.
Suppose a healthcare application predicts whether a patient has a disease (positive) or not (negative). A confusion matrix can help evaluate the model's accuracy in diagnosing the disease correctly and identify areas of improvement, such as reducing false positives to avoid unnecessary patient anxiety.
The confusion matrix is crucial for calculating additional metrics like precision, recall, and F1-score, which provide a more nuanced view of model performance compared to overall accuracy.
ROC Curve
The Receiver Operating Characteristic (ROC) curve is a graphical tool for evaluating the performance of a binary classification model. It displays the connection between the true positive rate (sensitivity) and the false positive rate (1-specificity) across different threshold settings.
Key Features:
The area under the ROC curve (AUC) is used as a single-value summary of the model's performance. An AUC value close to 1 indicates a highly effective model.
The curve helps visualize the trade-off between sensitivity (the ability to detect positive cases) and specificity (the ability to detect negative cases).
Use Case:
In email spam detection, an ROC curve helps fine-tune the threshold for classifying emails as spam or not, balancing the rates of false positives (legitimate emails marked as spam) and false negatives (spam emails allowed through).
The ROC curve is beneficial when the cost of false positives and negatives differs significantly. It enables decision-makers to select the optimal trade-off point based on the specific use case.
Importance of These Concepts
The confusion matrix and ROC curve go beyond simple accuracy metrics, offering a detailed and holistic evaluation of classification models. These tools help data scientists identify strengths and weaknesses in their models, enabling more targeted improvements. By using these concepts effectively, data scientists can ensure their models are reliable and tailored to meet the unique needs of the problem.
Understanding and applying these evaluation techniques is essential for building robust, high-performing machine learning systems in healthcare, finance, or e-commerce.
Conclusion
The journey to becoming a data scientist is demanding but immensely rewarding. This roadmap will give you a strong foundation in mathematics, programming, and machine learning and the soft skills needed to thrive in collaborative environments.
Success requires consistent effort and a commitment to learning. Begin your journey today and take confident steps toward a rewarding career in data science!
Soft Skills Learning Skills